Introducing DLP: a tool to help screen for and manage sensitive data
As part of its role in managing HDX, the Centre is aware of various types of sensitive data collected and used by our partners to meet needs in humanitarian operations. While organisations are not allowed to share personally identifiable information (PII) on HDX, they can share survey or needs assessment data which may (or may not) be sensitive due to the risk of re-identifying people and their locations. The HDX team manually reviews every dataset uploaded to the platform as part of a standard quality assurance (QA) process. As the platform has scaled and the range of data types shared by partners has expanded, screening for and identifying potentially sensitive, high-risk data has become more challenging.
To improve this process, we have integrated a detection tool from Google called Cloud Data Loss Prevention (DLP) into our screening process. Our goal is to screen all data uploaded to HDX for PII and other sensitive data. By using DLP, we are able to quickly scan the entire data file for different attributes (e.g. column headers that may indicate the presence of sensitive data) and identify potentially sensitive information. Datasets flagged as sensitive based on our criteria are marked ‘under review’ in the public interface of HDX and made inaccessible until the HDX team completes a manual review of the data. Over time, we will refine our use of DLP based on its performance, adding or removing key attributes to improve the detection of different forms of sensitive data.
The goal of this document is to provide an overview of DLP based on our experience. We specifically focus on identifying a use case for DLP, customizing DLP scans, testing DLP, and interpreting the results of DLP scans. We will continue to update this document based on what we learn in order to help other organisations integrate DLP or similar tools for screening humanitarian data into their own workflow.
NB: Google maintains extensive documentation of DLP that serves as a helpful technical resource when getting started. Our documentation supplements and contextualizes that resource by presenting a humanitarian use case of DLP. See “Annex: Navigating the official Google DLP documentation” at the end of this document for some tips on how to find what you’re looking for.
Preparing DLP: identify a use case and plan how to add DLP to your workflow
Google Cloud Data Loss Prevention (DLP) is a service designed to discover, classify, and protect sensitive information. It provides the ability to:
use over 120 built-in information type detectors – known as ‘infoTypes' – to identify sensitive data, and to define custom infoTypes using dictionaries, regular expressions, and contextual rules
detect sensitive data in various formats: text, structured text (e.g. tables), storage repositories, and even images
apply de-identification techniques and re-identification risk analyses to the data
Organisations should consider which of these capabilities is most relevant to their existing data management process before proceeding with DLP. While it may seem obvious, it is important to clearly describe the way(s) in which you expect DLP to improve your data management workflow before initiating the process to customize, deploy, and interpret the results of DLP.
Because the Centre already has a process and tool in place for assessing the risk of re-identification and applying disclosure control techniques to datasets (learn more on the SDC page), we chose to use DLP only for detection and classification of sensitive information.
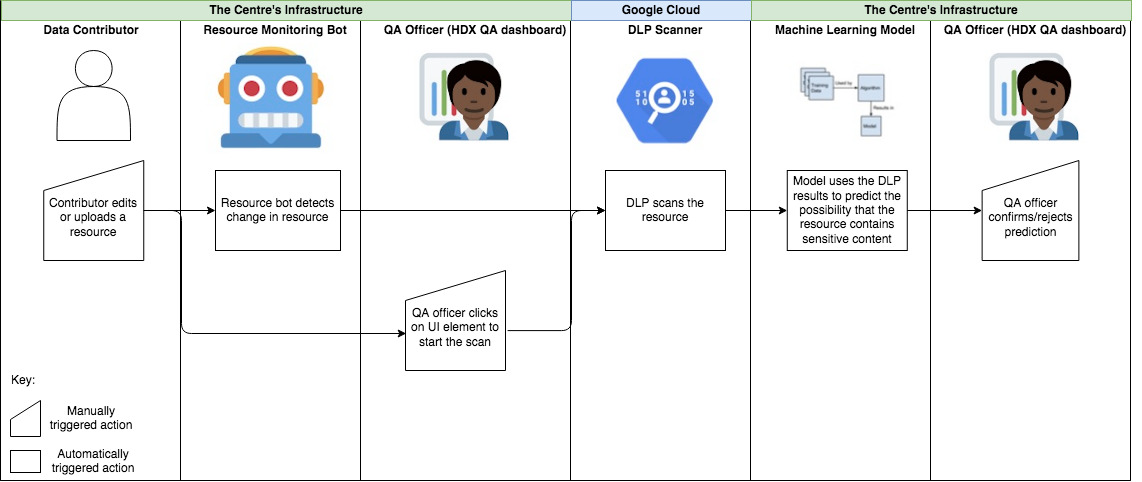
The diagram below shows how the Centre has integrated DLP into its standard QA process:
Customizing DLP: choose and create infoTypes for humanitarian contexts
Standard infoTypes: built-in detection mechanisms
Cloud DLP provides a set of over 120 built-in information types – known as ‘infoTypes’ – to define the sensitive data it can detect in a resource. There are both global infoTypes and country-specific infoTypes. For example, Location and Gender are global infoTypes, and France_Passport is a country-specific infoType that detects French passport numbers. Google maintains a list of all its built-in infoTypes here.
The first step in preparing a DLP scan is to choose a relevant set of standard infoTypes for your use case. The Centre currently includes the following standard infoTypes in its scans: AGE, EMAIL_ADDRESS, GENDER, ICD10_CODE, ICD9_CODE, IMEI_HARDWARE_ID, LOCATION, MEDICAL_TERM, PERSON_NAME, PHONE_NUMBER, STREET_ADDRESS, and CREDIT_CARD_NUMBER.
The Google DLP team controls the standard infoType detectors, meaning they may update them or add new ones periodically. In order to monitor these externally unavailable changes, the Centre recommends that organisations create a benchmark file to test at regular intervals.
Custom infoTypes: personalized detection mechanisms
While standard infoTypes are useful in certain contexts, custom infoTypes allow humanitarian organizations to specify and detect potentially sensitive keywords associated with affected people, humanitarian actors and/or a response.
Typically, custom infoTypes are dictionaries (e.g. text files containing lists of words or phrases, with each new line treated as its own unit). DLP only matches alphanumeric characters, so all special characters are treated as whitespace. For example, “household size” will match “household size,” “household-size,” and “household_size.” Dictionary words are also case-insensitive.
Custom infoTypes may also be regular expressions, enabling DLP to detect matches based on regular expression patterns.
The Centre has created and currently uses a set of twelve custom infoTypes:
Custom infoType | Format | Description |
DISABILITY_GROUP | Dictionary | A list of disabilities / disabled 'groups' or groups with limited 'functioning' per standard classification |
EDUCATION_LEVEL | Dictionary | A list of different indicators for level of education (e.g. ‘OSY’ for out of school youth) |
GEO_COOR | Regular expression | Latitude and longitude coordinates |
HDX_HEADERS | Dictionary | A set of commonly seen column names that may indicate presence of sensitive data, e.g. Key Informant |
HH_ATTRIBUTES | Dictionary | Words indicating specific attributes of a household (e.g. ‘Child_Headed_Household’) |
HXL_TAGS | Regular expression | A subset of all existing HXL tags that have been associated with (potentially) sensitive data. |
MARITAL_STATUS | Dictionary | A list of marital statuses |
OCCUPATION | Dictionary | A list of employment statuses and common occupations |
PROTECTION_GROUP | Dictionary | Include different indicators for populations of concern (e.g. ‘pregnant’ or ‘unaccompanied child’) |
RELIGIOUS_GROUP | Dictionary | A list of religions / religious groups in different languages |
SEXUALITY | Dictionary | A list of sexual orientations |
SPOKEN_LANGUAGE | Dictionary | A list of spoken languages |
The dictionary infoTypes are set up to match two types of information: the column names of key variables and the values of each key variable. For example, SPOKEN_LANGUAGE matches “mother tongue” and “language” as well as specific language names. Similarly, MARITAL_STATUS matches the term “marital status” as well as “married” and “widowed.”
Unlike the standard infoTypes, the custom infoTypes must be maintained by your organisation. Some custom infoTypes are essentially complete from the outset; others may require updates over time as your organisation learns and adapts.
The Centre has organized its custom infoTypes into three main categories, as described in the table below: comprehensive, comprehensive in context, and not comprehensive.
Category | Description |
(1) Comprehensive: GEO_COOR (regex) HXL_TAGS (regex) PROTECTION_GROUP RELIGIOUS_GROUP SEXUALITY SPOKEN_LANGUAGE | Static. No updates needed unless errors or omissions are found. Example: SPOKEN_LANGUAGE will not need to be updated unless certain rare or dying languages appear to be missing. |
(2) Comprehensive in context: DISABILITY_GROUP EDUCATION_LEVEL MARITAL_STATUS | Functionality will be dependent on the correct context of key terms. Example: “single” is not exclusively a marital status, just as “primary” is not always an education level. |
(3) Not comprehensive: OCCUPATION HH_ATTRIBUTES HDX_HEADERS | Difficult to capture all possibilities upfront; may need updates as more datasets are scanned. Example: “child_headed”, “families headed by children”, and “hohh child” all express the same household attribute; different data contributors may have their own versions. |
Over time, we will refine our use of DLP based on its performance. This process will involve adding, updating, or removing custom infoTypes across these three categories to improve the detection of different forms of sensitive data.
Testing and Refining DLP: assess the suitability of the results for your use case
Once an organisation has selected standard infoTypes and created custom infoTypes to use in their scans, it is time to test DLP to make sure the output meets their requirements.
Given data input, DLP returns details about 1) the infoTypes detected in the text; 2) a likelihood, ranging from VERY_UNLIKELY to VERY_LIKELY with default POSSIBLE, that indicates how likely it is that the data matches the given infoType; and 3) a quote, which is the actual string of data identified as the infoType.
Because organisations will focus on the DLP capabilities most relevant to their existing data management process, there is no one-size-fits-all approach to testing. However, we recommend answering two key questions before deploying DLP:
Can DLP detect all or most types of sensitive data that we encounter in our existing data management process?
How accurately do the detected infoTypes from a scan match the PII and key variables we are trying to catch?
Over the course of 4 months, the Centre conducted 6 rounds of testing on a set of 70 sensitive datasets and 70 placebo datasets to assess these questions. While the answers may seem obvious from an initial glance at the infoType descriptions, we found it crucial to observe the detection mechanisms in action. For example, when we used the LAST_NAME infoType in early stages of testing, we looked at the quotes and realized it was flagging both refugee camp names and actual surnames. Because microdata uploaded to HDX frequently contains camp names, we determined that the LAST_NAME infoType was not particularly helpful to include in the Centre’s scans. Additionally, we expected the LOCATION infoType to detect GPS coordinates, but found that it did not do so in practice. In other words, DLP did not initially detect a type of sensitive data we were looking for. Because of this, we adjusted our initial assumptions and created a custom infoType to detect longitude and latitude coordinates.
Your organisation may ultimately differ from the Centre in your answers to the above questions, but these types of contextual observations and decisions are what underlie a robust testing process for DLP. Accordingly, the process should draw upon cross-functional expertise from teams across your organisation, not just the data scientists. At the Centre, the Development team managed the technical details of DLP while both the Data Partnerships and the Data Responsibility teams analyzed the outputs of the scans.
Interpreting and Using the Output of DLP: develop actionable criteria for classifying data as sensitive
Even once an organisation is confident that DLP accurately detects the types of sensitive data present in their context, the output of a DLP scan alone does not determine whether a given dataset is sensitive. Ultimately, each organisation needs to define its own criteria for interpreting the DLP output (e.g. does the presence of a single instance of an infoType mean a dataset is sensitive?)
Depending on the number of standard and custom infoTypes included in the inspection, the raw output of a DLP scan may comprise anywhere from thousands to millions of rows of detected matches. On average, it took our team 48 hours to review the full results of a test scan (which included 70 sensitive datasets and 70 placebo datasets). While reviewing the results of a scan for a single dataset would take much less time, this process still proved onerous and was non-conducive to our use case of reaching a binary decision about a dataset’s sensitivity. Based on this difficulty, we proceeded to explore whether we could create a complementary tool or algorithm to classify a dataset as sensitive using the training data generated through DLP testing.
A machine learning approach
To interpret the raw output of a DLP inspection scan, the Centre has developed a robust model that averages the results of a random forest model, a generalized linear model, and a gradient boosting model to predict the possibility that a dataset is sensitive or non-sensitive. We generated the training data for this model from our 6 rounds of testing on 70 sensitive datasets and 70 placebo datasets. The model uses detected infoTypes, likelihoods, and quotes as the main elements in its analysis.
When a new resource is uploaded to HDX, the output of the DLP scan is used by the model to predict the probability that the dataset is sensitive. The HDX team then manually reviews the new datasets for sensitivity and accordingly accepts or rejects the model’s classification.
As the model is used to classify more and more datasets, its prediction values should become more and more accurate. If we start to see higher levels of model error – e.g. if the QA officer often disagrees with the model’s classification of sensitivity – we will revisit our DLP testing process, may reevaluate our use of certain standard and custom infoTypes, and will retrain the model accordingly.
In this way, we will refine our use of DLP over time based on its performance. We will continue to update this document based on what we learn.
Annex: Navigating the official Google DLP documentation
Google maintains extensive documentation of Cloud DLP, including quickstart guides, references, and code samples. The links below provide a simple way to navigate that documentation and assess which capabilities are relevant in your organization’s context.
Inspection
Of text strings
Of structured text, like tables
Of images
Redaction
Replace any sensitive data (any chosen infoTypes) with placeholder text
De-identification
Techniques include:
Masking sensitive data by partially or fully replacing characters with a symbol, such as an asterisk (*) or hash (#)
Replacing each instance of sensitive data with a token, or surrogate, string
Encrypting and replacing sensitive data using a randomly generated or pre-determined key
Within structured text (tabular data):
Scan a single column for a certain data type instead of the entire table structure
Transform a single column
e.g. bucketing a column of scores into increments of 10
Transform a column based on the value of another
e.g. redacting a score for all beneficiaries over age 89
Anonymize all instances of an infoType in a column
Remove/suppress a row entirely based on the content that appears in any column
e.g. hide all rows pertaining to beneficiaries over age 89
Transform findings only when specific conditions are met on another field
e.g. redact PERSON_NAME if the value in AGE column > 89
Transform findings using a cryptographic hash transformation
Risk analysis
4 techniques to quantify the level of risk associated with a dataset:
k-anonymity: A property of a dataset that indicates the re-identifiability of its records.
l-diversity: An extension of k-anonymity that additionally measures the diversity of sensitive values for each column in which they occur.
k-map: Computes re-identifiability risk by comparing a given de-identified dataset of subjects with a larger re-identification—or "attack"—dataset.
Delta-presence (δ-presence): Estimates the probability that a given user in a larger population is present in the dataset.
Acknowledgement: The Centre’s work to develop an improved technical infrastructure for the management of sensitive data on HDX was made possible with support from the Directorate-General for European Civil Protection and Humanitarian Aid Operations (DG ECHO). Development of this technical documentation was supported through the United Kingdom Foreign, Commonwealth and Development Office (FCDO)’s COVIDAction programme.