This document is intended as a collection of procedures and resources to guide the curation of Data Completeness instances (henceforth, Data Grids) which can be activated for any location page on HDX (by a sysadmin). This document and others linked from it, should evolve to capture best practices and any other useful info learned as the data grid curators do their work.
Once activated for a given location page, the Data Grid will appear and will be using a default recipe (based on tags) to fill the data grid. However, tags are seldom enough to accurately gauge if a dataset meets the requirements of a given data grid. Curation, then, is the process of customizing a specific location's data grid so that the datasets included in the data grid meet the defined requirements for the subcategory. That customization is done by editing the recipe yaml file (which is format that is friendly to both humans and machines).
Resources
- Procedure document (this document)
- Data Completeness Definitions Document
- Quality Checklist (below)
- YAML editing examples (below)
- Github Repository
- YAML Validator
Process Overview
The basic curation process is outlined below:
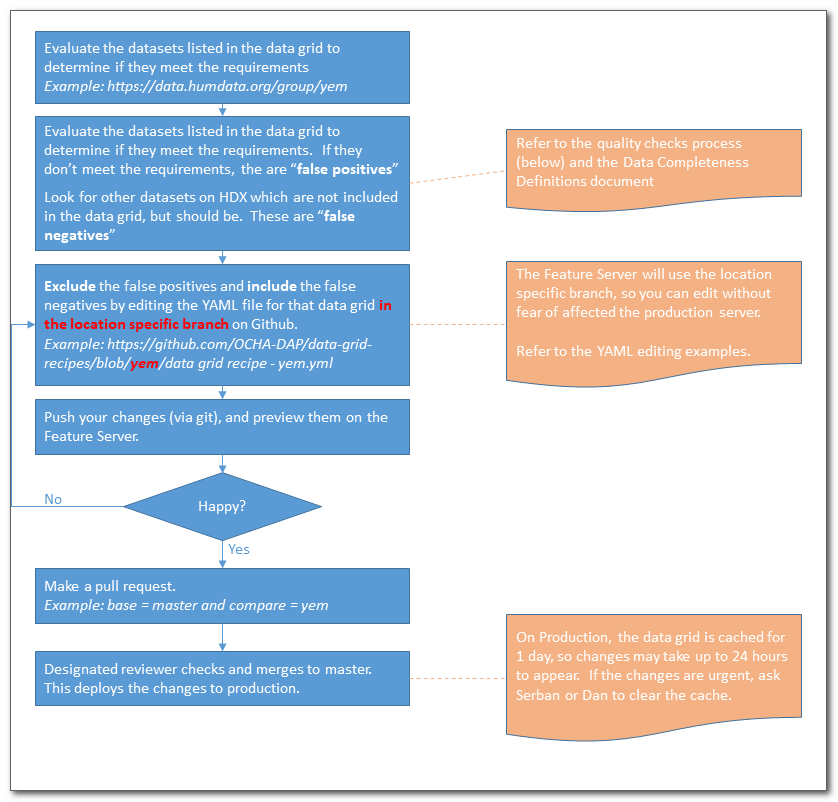
Data Grid Instances to be Curated
There may be more on the feature server for testing purposes, but the ones listed below should be the only active ones on the production server.
| Country | Production Data Grid | Feature Server Data Grid | Curator(s) | Last check date |
|---|---|---|---|---|
| Yemen | Production: yem | Feature: yem | ||
| Sudan | Production: sdn | Feature: sdn | Amadu | |
| Indonesia | Production: idn | Feature: idn | Amadu | |
| Somalia | Production: som | Feature: som | Nafi | |
| Colombia | Production: col | Feature: col | Elliot | |
| Philippines | Production: phl | Feature: phl | Joseph & Amadu | |
| Afghanistan | Production: afg | Feature: afg | Amadu | |
| Bangladesh | Production: bgd | Feature: bgd | Faizal & Amadu | |
| Chad | Production: tcd | Feature: tcd | Amadu | |
| Mozambique | Production: moz | Feature: moz | Amadu | |
| Venezuela | Production: ven | Feature: ven | Amadu | |
| Democratic Repubic of the Congo | Production: cod | Feature: cod | Godfrey & Amadu | |
| Central African Republic | Production: caf | Feature: caf | Khasif & Amadu |
Quality Checks Process
Each dataset that is a candidate for data grid has to be evaluated to determine if it fully meets the requirements to be included, partially meets the requirements, or does not meet them at all. The outcome determines what actions have to be taken in the YAML file to inlcude or exclude the file, and any comments to be recorded for users to understand where the dataset falls short. Below the process diagram, you will find more details on each quality check.
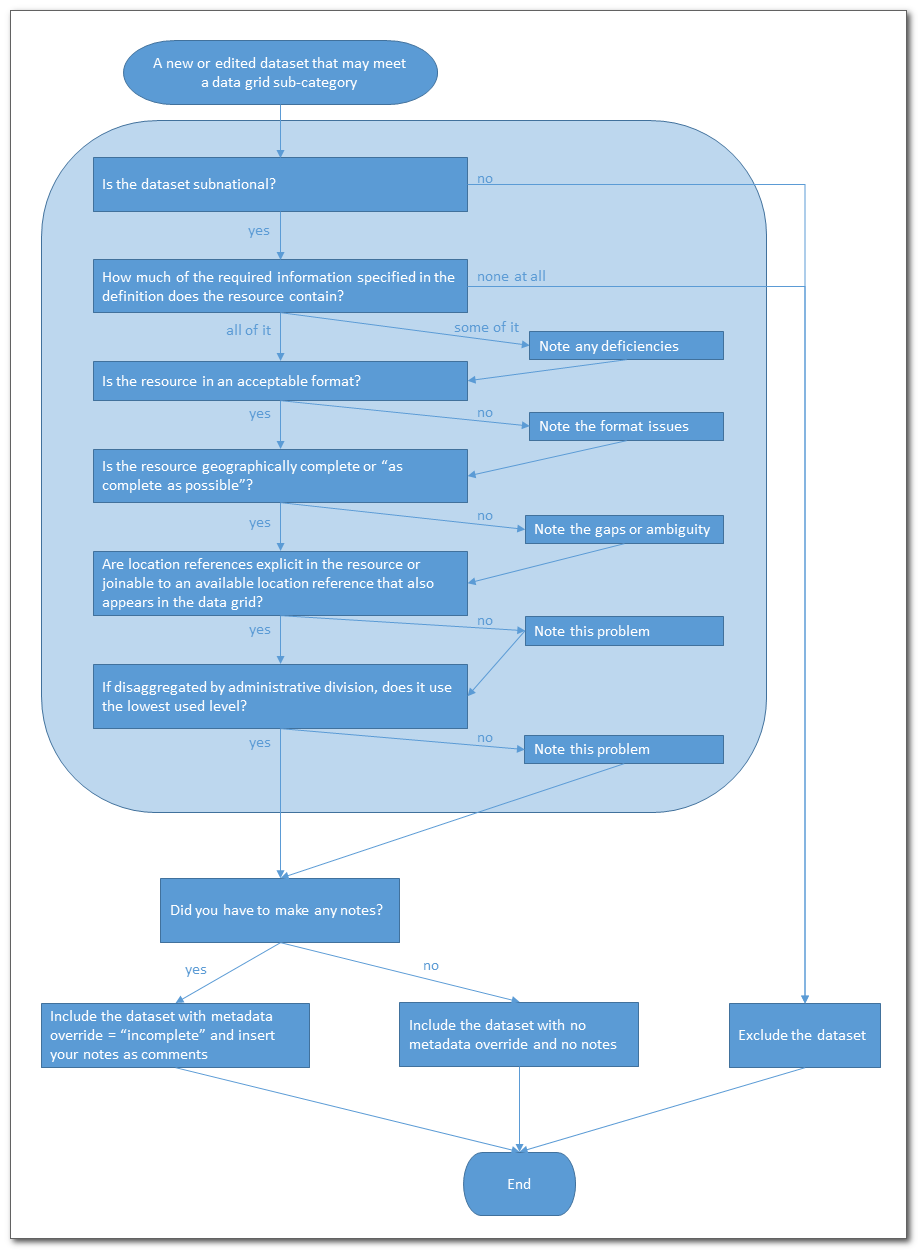
Details on each quality check
Is the dataset subnational?
This one is straightforward. National level statistics are by definition excluded from data grid. The extent to which it needs to be subnational is handled further down this list.
How much of the required information specified in the definition does the resource contain?
Look at the sub-category definition and determine if the definition is met fully, partially, or not at all. If a lack of clear field names and/or a data dictionary make it hard to be sure, the dataset can be excluded or included as partially meeting the requirements.
Note: if t complete coverage can be obtained by combining several datasets (for example: several different 3Ws, one for each cluster with all clusters being covered), then all the datasets can be included but marked as "incomplete" with the same comment. The logic here is that someone should be combining these datasets.
Suggested comment language for a partial fit:
- Dataset contains data about A but does not include the expected data about B.
- Dataset appears to contain data about A but the units are not clear from the field name or metadata.
- Dataset contains data about all active clusters except Protection.
Is the resource in an acceptable format?
For tabular data, the the dataset should be tidy in the sense that field names and data rows should be easy to determine. There shouldn't be subtotal rows interspersed with data rows. For a format like xls or xlsx, the required data for a single sub-category should be on the same tab, and if not this should be noted in the comments. For tabular data with coordinates, the x and y columns (usually longitude and latitude) should be in decimal degree format and separated into two columns, and if not, this should be noted in the comments.
For geographic data, the data should be zipped shapefile, geojson, or geodatabase. Other somewhat common formats (kml, kmz, but not raster formats) could be accepted, with a comment.
Suggested comment language for a partial fit:
- The required fields are present, but not consolidated into a single tab.
- Non-data rows (sub-totals) are included within the data.
- The latitude and longitude coordinates are combined in a single field.
- The latitude and longitude coordinates are not presented in decimal degree format.
- The geopackage format is not a preferred format.
- The dataset is only available in a geographic format, and tabular data is preferred for this subcategory.
Is the resource geographically complete or “as complete as possible”?
This one is trickier than it sounds. There are two ways to assess completeness:
- If there is a comprehensive list of locations to compare against (such as admin units), does the resource provide the necessary information for all admin units at whatever levels are being covered. Missing values for one or more admin divisions can be acceptable if the meaning of a missing value is defined in the metadata somewhere. For example, "districts where cholera has never been recorded are assumed to be 0 and not included in the data". The value of "missing" is defined as having values 0, so the data is complete. However something like "districts not included in the data are still being evaluated" would indicate no value for the missing districts. Such a dataset should be included as "incomplete", but with the gap noted as a comment.
- If there is not a comprehensive list of locations to compare against (such as a list of health facilities or security incidents), does the dataset claim to be complete, or at least "as complete as possible"? If so, the dataset can be included with no comment. However is no such claim is made, or significant caveats are given about incompleteness, then the dataset should be included as "incomplete" with a comment. For example, any OSM extract will almost certainly be considered "incomplete" for this test and OSM does not usually make claims about completeness (though there could be exceptions for some locations where concerted efforts have been made by groups like HOT).
Suggested comment language for a partial fit:
- Dataset does not appear to cover all admin X units and is therefore assumed to be incomplete.
- Dataset covers a limited area.
- Some "no data" values occur, but the meaning of these values not defined in the metadata.
- It is not clear from metadata if this dataset attempts comprehensive coverage and is therefore assumed to be incomplete.
- Dataset is not considered complete by its contributor.
- OpenStreetMap data relies on user contributions and may not be comprehensive for all areas. Dataset does not always contain data about practicability of a road.
- Dataset is limited to captials of administrative divsions.
Are location references explicit in the resource or joinable to an available location reference that also appears in the data grid?
If a dataset contains references to location, are those locations defined in the dataset (such as latitude and longitude columns)? If not, then do p-codes or some other identifier make it possible to join this dataset to a location reference that is available in data grid (such as a COD admin boundary or a facilities list)? Datasets with partially successful joins should be included in data grid as incomplete with a comment.
Suggested comment language for a partial fit:
- Dataset is disaggregated using administrative divisions (admX), however not all rows successfully join to the available dataset for that admin level.
- Dataset is disaggregated using specific locations, but no corresponding dataset defining those locations is available.
- Dataset is disaggregated geographically, but inconsistently.
If disaggregated by administrative division, does it use the lowest-used level?
If most of the data for the country uses admin level 3, but the dataset in question is only disaggregated to admin level 1, the dataset can be included as "incomplete" with a comment.
Suggested comment language for a partial fit:
- Dataset is not disaggregated to the most commonly used level for this location (admX).
Some standard language for common datasets:
OurAirports
Ourairports data relies on user contributions and may not be comprehensive.
HOTOSM Road Extracts
OpenStreetMap data relies on user contributions and may not be comprehensive. Dataset does not always contain data about practicability of a road.
Interaction Member Activities in (Country)
Dataset contains data about Interaction member organizations but not other organizations working in the country. Dataset is disaggregated geographically, but inconsistently.
UNOSAT Damage Assessments
There can be a large number of these datasets, many of them out of date. Only include these datasets if the "date of dataset" is recent (probably within 6 months, but that could vary depending on the nature of the crisis). Generally speaking, these datasets cover only a small area (a single city or town per dataset) and therefore should have this comment:
Dataset covers a limited area.
Editing the YAML File
Overview
In the normal practice of curation, only the include rules, exclude rules and metadata overrides need to be edited. Metadata overrides can only apply to datasets that are included based on the include rules.
Here's an annotated example for the Baseline Population subcategory:
#BASELINE POPULATION
- name: baseline_population
title: Baseline Population
description: Total population aggregated by administrative division.
rules:
include: #adds to the data grid any dataset that matches the country of the data grid (yemen in this case), one or more of the specified tags, and is subnational
- (tags:"population" AND subnational:1)
- (tags:"population statistics" AND subnational:1)
- (tags:"demographics" AND subnational:1)
exclude: # removes from the data grid any datasets matching these tags. Note the last one in this list is not based on tags (see comment in line)
- (tags:"people in need")
- (tags:"people affected")
- (tags:"displaced people")
- (tags:"interally displaced people")
- (tags:"hno")
- (tags:"humanitarian needs overview")
- (tags:"humanitarian needs overview - hno")
- (organization:"worldpop" AND title:" - Population" AND res_format:"zipped geotiff") # removes a specific type of worldpop dataset based on the org name,
# resource format, and a pattern in the dataset title
metadata_overrides: # this section modifies how a particular dataset is displayed in the data grid
- dataset_name: yemen-admin1-combined-food-insecurity-phase-2017-and-population-estimates-2015-2020 #specifies which dataset to modify the display of. It
# must already be included from the 'rules' section above, otherwise this is ignored.
display_state: incomplete # forces the dataset to be displayed with the "hashed" color, not solid blue.
comments: The dataset is only available in a GIS format, and tabular data is preferred for this subcategory. # These comments will appear when
# someone hovers over the dataset in data grid.
The YAML file for each country (and the default YAML file from which they are derived), create a hierarchy:
- A top level Data Grid element which has
- One or more Category Elements (like "Admnistration" or "Population and Socio-Economic") which have
- One or more Subcategory Elements (like "Administrative Divisions" or "Populated Places") which have
- A set of rules for including and excluding datasets based on tags, dataset names, or any other query supported by solr. These rules are in the format of an fq query and therefore can be tested using the hdx site. For example to test the include rule (tags:"populated places" AND sunbnational:1) for Indonesia, use https://data.humdata.org/search?fq=(tags:"populated places" AND subnational:1 AND groups:idn)
- One or more include rules which specify one or more queries the results of which will be added to the data grid. These rules are in the format of an fq query and therefore can be tested using the hdx site. For example to test
- Zero or more exclude rules which specity datasets that should not be allowed in the data grid
- A set of metadata overrides which refer to datasets already included by the rules and define how they are displayed and comments that are displayed along with them.
- A set of rules for including and excluding datasets based on tags, dataset names, or any other query supported by solr. These rules are in the format of an fq query and therefore can be tested using the hdx site. For example to test the include rule (tags:"populated places" AND sunbnational:1) for Indonesia, use https://data.humdata.org/search?fq=(tags:"populated places" AND subnational:1 AND groups:idn)
- One or more Subcategory Elements (like "Administrative Divisions" or "Populated Places") which have
- One or more Category Elements (like "Admnistration" or "Population and Socio-Economic") which have
In the normal practice of curation, only the include rules, exclude rules and metadata overrides need to be edited.
Style Notes
- Always end comments and descriptions with a period. There will be some automatic notes added at the end (for freshness), so without the period, this would look odd.
- At the beginning of a sentence say "Dataset . . . " not "The dataset . . ." for brevity.
- refer to admin levels as adm1 adm2, etc
- refer to "administrative divisions" instead of "administrative units" or "admin boundaries"