Introduction
We would like to be able to determine how fresh is the data on HDX for two purposes. Firstly, we want to be able to encourage data contributors to make regular updates of their data where applicable, and secondly, we want to be able to tell users of HDX how up to date are the datasets in which they are interested.
Important fields
Field | Description | Purpose |
|---|---|---|
data_update_frequency | Dataset expected update frequency | Shows how often the data is expected to be updated or at least checked to see if it needs updating |
last_modified | Resource last modified date | Indicates the last time the resource was updated irrespective of whether it was a major or minor change |
dataset_date | Dataset date | The date referred to by the data in the dataset. It changes when data for a new date comes to HDX so may not need to change for minor updates |
There are two dates that data can have and this can cause confusion, so we define them clearly here:
Date of update: The last time the data was was looked at to confirm it is up to date. The ideal is that the date of update history corresponds with what is selected in the expected update frequency. This is last_modified.
Date of data: The actual date of the data. An update could consist of just confirming that the data has not changed. This is dataset_date.
When we talk about "update time", we are referring to option 1.
The method of determining whether a resource is updated depends upon where the file is hosted. If it is hosted by HDX, then the update time is recorded, but if externally, then there can be challenges in determining if a url has been updated or not.
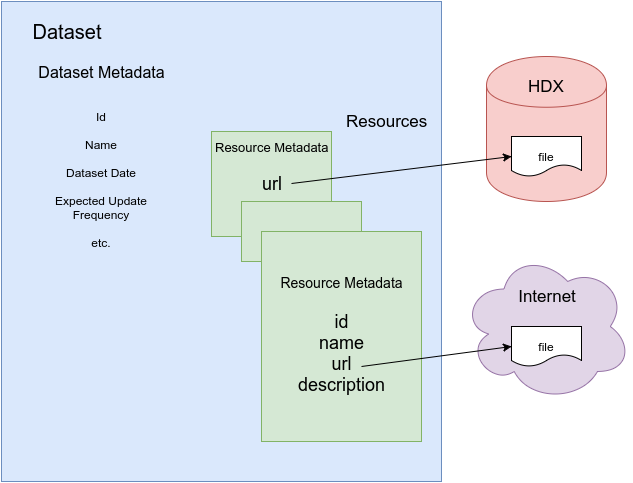
Once we have an update time for a dataset's resources, we can calculate its age and combined with the update frequency, we can ascertain the freshness of the dataset.
Dataset Aging Methodology
A resource's age can be measured using today's date - last update time. For a dataset, we take the lowest age of all its resources. This value can be compared with the update frequency to determine an age status for the dataset.
Thought had previously gone into classification of the age of datasets. Reviewing that work, the statuses used (up to date, due, overdue and delinquent) and formulae for calculating those statuses are sound so they have been used as a foundation. It is important that we distinguish between what we report to our users and data providers with what we need for our automated processing. For the purposes of reporting, then the terminology we use is simply fresh or not fresh. For contacting data providers, we must give them some leeway from the due date (technically the date after which the data is no longer fresh): the automated email would be sent on the overdue date rather than the due date. The delinquent date would also be used in an automated process that tells us it is time for us to manually contact the data providers to see if they have any problems we can help with regarding updating their data.
Update Frequency | Dataset age state thresholds (how old must a dataset be for it to have this status) | |||
|---|---|---|---|---|
Fresh | Not Fresh | |||
Up-to-date | Due | Overdue | Delinquent | |
Daily | 0 days old | 1 day old due_age = f | 2 days old overdue_age = f + 2 | 3 days old delinquent_age = f + 3 |
Weekly | 0 - 6 days old | 7 days old due_age = f | 14 days old overdue_age = f + 7 | 21 days old delinquent_age = f + 14 |
Fortnightly | 0 - 13 days old | 14 days old due_age = f | 21 days old overdue_age = f + 7 | 28 days old delinquent_age = f + 14 |
Monthly | 0 -29 days old | 30 days old due_age = f | 44 days old overdue_age = f + 14 | 60 days old delinquent_age = f + 30 |
Quarterly | 0 - 89 days old | 90 days old due_age = f | 120 days old overdue_age = f + 30 | 150 days old delinquent_age = f + 60 |
Semiannually | 0 - 179 days old | 180 days old due_age = f | 210 days old overdue_age = f + 30 | 240 days old delinquent_age = f + 60 |
Annually | 0 - 364 days old | 365 days old due_age = f | 425 days old overdue_age = f + 60 | 455 days old delinquent_age = f + 90 |
Never | Always | Never | Never | Never |
Live | Always | Never | Never | Never |
As Needed | Always | Never | Never | Never |
Here is a presentation about data freshness from January 2017 that provides a good introduction.
Data Freshness Architecture
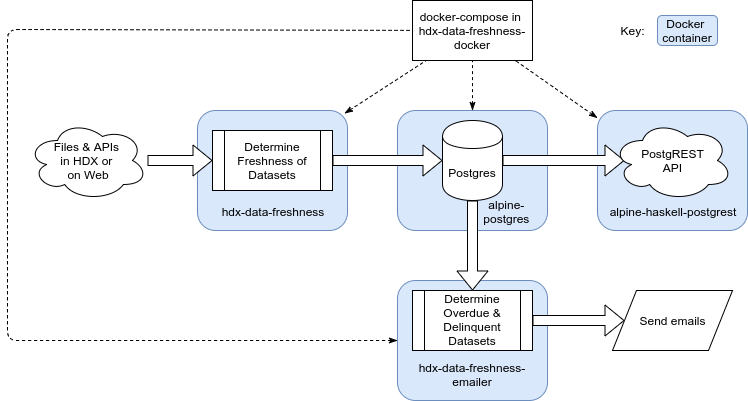
Data freshness consists of a database, REST API, freshness process and freshness emailer.
There is a docker container hosting the Postgres database (https://hub.docker.com/r/unocha/alpine-postgres/ - 201703-PR116) and a port is open on there to allow connection from external database clients (hdxdatateam.xyz:5432). There is a another Docker container (https://hub.docker.com/r/mcarans/alpine-haskell-postgrest/) that exposes a REST API to the database (http://hdxdatateam.xyz:3000/) - the docker setup for this is here: https://github.com/OCHA-DAP/alpine-haskell-postgrest. The freshness process and freshness emailer are also within their own Docker containers. The docker-compose that brings all these containers together is here: https://github.com/OCHA-DAP/hdx-data-freshness-docker.
Here is an overall view of the architecture:
Data Freshness Process
Data Freshness Emailer
Completed Work
Data Freshness Roadmap
Statistics
References
Using the Update Frequency Metadata Field and Last_update CKAN field to Manage Dataset Freshness on HDX:
https://docs.google.com/document/d/1g8hAwxZoqageggtJAdkTKwQIGHUDSajNfj85JkkTpEU/edit#
Dataset Aging service:
https://docs.google.com/document/d/1wBHhCJvlnbCI1152Ytlnr0qiXZ2CwNGdmE1OiK7PLzo/edit
https://github.com/luiscape/hdx-monitor-ageing-service
University of Vienna paper on methodologies for estimating next change time for a resource based on previous update history:
https://www.adequate.at/wp-content/uploads/2016/04/neumaier2016ODFreshness.pdf
University of Vienna presentation of data freshness: